
Data Science ist populär: Was verbirgt sich hinter Data Science? Warum ist Data Science wichtig und Wie arbeiten Data Scientists heute?
Eine Einordnung der wichtigsten Begriffe, Fakten und aktuellen Trends.

Was: Data Science?
Data Science ist eine handwerklich hochwertige Dienstleistung, die die nutzbringende Verwertung von Daten aller Art anstrebt. Ziele von Data Science sind Erkenntnisgewinn, Prognoseerstellung, Entscheidungsoptimierung sowie schließlich die Automatisierung von Systemen, Dienstleistungen und Prozessen.
Data Science Projekte basieren idealerweise immer auf einer konkreten fachlichen Frage- oder Problemstellung.
Von dieser Fragestellung ausgehend, werden relevante Daten gesammelt resp. ausgewählt, bereinigt, ggf. aggregiert / aufbereitet, visualisiert sowie hinsichtlich etwaiger Muster analysiert (Mustererkennung). Aus den aufbereiteten Daten werden Modelle unterschiedlicher Komplexität abgeleitet, die die Abbildung unabhängiger Input-Variablen auf ein oder mehrere Ziel-Variablen mathematisch beschreiben. Die abgeleiteten Modelle können anschließend auf unbekannte, gleich strukturierte Datensätze angewendet werden. Auf diese Art und Weise werden Voraussagen für zukünftige Entwicklungen resp. für bisher nicht erprobte Konstellationen möglich sowie – darauf aufbauend – die Formulierung von Handlungsempfehlungen.
Die abgeleiteten Modelle können für entsprechende Anwendungsfälle in IT-Systemen integriert und regelmäßig automatisiert ausgeführt werden. Werden die abgeleiteten Modelle regelmäßig automatisiert ausgeführt, ist eine kontinuierliche Prüfung, Wartung und Weiterentwicklung der Modelle notwendig.
Begriffliche Einordnung
Die einzelnen Ausprägungen werden begrifflich eingeordnet:
- die Analyse und Visualisierung von Daten (Mustererkennung) wird als Exploratory Data Analysis (EDA) bezeichnet. Die EDA ist der Schwerpunkt von Data Science im engeren Sinne.
- die auf der EDA aufbauende Modellerstellung mit dem Ziel der Prognose / Decision Making wird als Predictive Analytics resp. als Machine Learning (ML) bezeichnet.
- Künstliche Neuronale Netze (Deep Learning) sind besonders leistungsfähige Modelle, die die bisher gebräuchlichen, explizit formulierten Modelle auf Grund der größeren Prognose-Leistungsfähigkeit ergänzen resp. ablösen. Sie kommen zum Einsatz, wenn große Mengen unstrukturierter Daten und/oder komplexe Fragestellungen analysiert werden. Nachteil der neuronalen Netze ist die fehlende Transparenz hinsichtlich Interpretierbarkeit / Verständlichkeit sowie die notwendige Menge an Trainingsdaten.
- Convolutional Neural Networks (CNN) sind auf die maschinelle Verarbeitung von Bild- und Videodaten (Computer Vision) spezialisierte Modelle, bei denen zunächst über ein systematisches Abtasten mit Filtern Features und deren Positionen in den Eingangsbildern in Feature Maps erfasst und aus diesen Sekundärinformationen dann in einem zweiten Schritt die abhängigen Variablen über ein neuronales Netz abgeleitet werden. Herkömmliche neuronale Netze, die direkt auf den Inputdaten agieren, stoßen bei der Verarbeitung von Bild- und Videodaten auf Grund des notwendigen Rechneraufwandes an ihre Grenzen.
- Natural Language Processing (NLP) bezeichnet die Analyse und Verarbeitung natürlicher Sprache mit Hilfe spezieller Sprachmodelle. Als Königsdisziplin gilt die freie Erstellung neuer Texte nach inhaltlichen und stilistischen Vorgaben.
- Die vollautomatische Entscheidungsfindung wird der Künstlichen Intelligenz (KI) zugeordnet. Eine (zukünftige) „starke KI“, die das Leistungsniveau des menschlichen Gehirns erreicht, wird als transformative KI bezeichnet. Grundlage hierfür sind auf den Sprachmodellen aufbauenden multimodalen KI-Modelle (wie Aleph Alpha), die Computer Vision und NLP miteinander verknüpfen.
Geschichtliche Entwicklung
Obwohl die heute allgemein anerkannten Grundprinzipien von Data Science u.a. im Rahmen von datengetriebenen Arbeiten aus dem Bereich der Naturwissenschaften bereits lange Zeit methodisch vorweggenommen wurden, hat die Disziplin Data Science erst in den letzten Jahren die heutige enorme Aufmerksamkeit erreicht. Dazu beigetragen haben:
- eine signifikante Zunahme umfangreicher digitaler Datenbestände – u.a. als Ergebnis von IoT/IIoT, Social Media, eCommerce
- eine kontinuierliche Steigerung verfügbarer Rechenleistung – sowohl im Server/Desktopbereich als auch bei stromsparenden Einplantinencomputern für Echtzeitanalysen in Embedded Systemen
- die zunehmende Verfügbarkeit freier Bibliotheken, Frameworks, vortrainierter Modelle sowie kommerzieller MLaaS-Plattformen
Allgemein wird angenommen, dass Systeme mit datenbasierter Künstlichen Intelligenz (KI) die menschliche Intelligenz in absehbarer Zeit „erreichen“ und „übertreffen“ können und damit ein neues Kapitel in der Zusammenarbeit Mensch / Maschine aufgeschlagen werden wird. Der Sieg des Programms AlphaGo über den stärkster Go-Spieler der Welt Lee Sedo (März 2016), das KI-Sprachmodell GPT-3 von OpenAI LP (Mai 2020) sowie die genaue Proteinstrukturvorhersagen von AlphaFold (CASP 14, November 2020) gelten als Meilensteine auf diesem Weg.
Andererseits hat es der Geschichte der KI seit den 1950er Jahren bereits mehrfach Phasen gegeben, in denen hochgesteckte Erwartungen geweckt aber dann doch nicht erfüllt wurden. Heute sind (vermeintlich) fehlende Business Cases als auch kulturell begründete Einschränkungen limitierende Faktoren für den Einsatz von KI in traditionellen Branchen und Gesellschaftsbereichen.
Data Science und EU-Datenschutz-Grundverordnung
Durch kontinuierliches Aufzeichnen von Benutzeraktivitäten und -positionen sowie die systematische Verknüpfung großer Datenmengen mithilfe leistungsfähiger Algorithmen können detaillierte personenbezogene Benutzerprofile abgeleitet und missbräuchlich verwendet werden. Die DSGVO schränkt deshalb die Sammlung, Speicherung, Verarbeitung und Weitergabe personenbezogener Daten ein:
- jede Erhebung personenbezogener Daten hat zweckbestimmt zu erfolgen. Sie ist generell nur dann erlaubt, wenn ein berechtigtes Interesse für die Erhebung vorliegt, und sie muss sich auf das für den konkreten Zweck notwendige Maß beschränken.
- die Speicherung der Daten ist auf den für den konkreten Zweck notwendigen Zeitraum zu beschränken, anschließend müssen die Daten gelöscht werden. Darüber hinaus hat jede betroffene Person jederzeit das Recht, das Löschen der eigenen Daten explizit zu veranlassen (Recht auf Vergessen)
- Datenspeicherung und -verarbeitung müssen unter Berücksichtigung der Gewährleistung der Privatsphäre resp. des Datenschutzes nach aktuellen Standards erfolgen. Datenspeicherung und -verarbeitung müssen transparent und nachvollziehbar sein.
Die DSGVO gilt unabhängig vom Sitz der Institution/vom Wohnort der Person, die Daten sammelt und/oder verarbeitet, wenn die Daten europäische Personen betreffen. Sie zielt auch auf Datensätze, die selbst keine personenbezogenen Daten enthalten aber die Ableitung solcher Daten über die Kombination mehrerer Datensätze erlauben.
Data Science und DSGVO stehen in einem offensichtlichen Spannungsfeld zueinander, nicht zuletzt auch durch die fehlende detaillierte Nachvollziehbarkeit der Funktionalität Neuronaler Netze. Lösungen werden z.B. mit Ansätzen einer Explainable Artificial Intelligence (XAI) diskutiert.
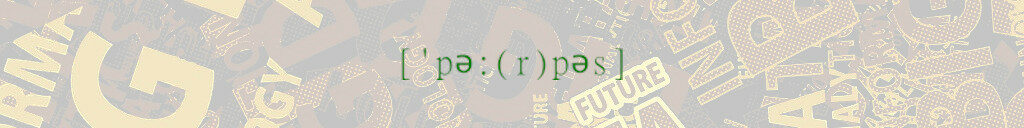
Warum: Data Science?
Date Science erklärt einerseits beobachtete/gemessene Phänomene und ermöglicht andererseits nachvollziehbare, datengetriebene operative und strategische Entscheidungen – auch automatisiert und in Echtzeit. Wo eine Vollautomatisierung nicht möglich oder nicht erwünscht ist, können Digitale Assistenzen menschliche Experten in Echtzeit unterstützen. Datenbasierte Geschäftsmodelle bilden zusammen mit dem IoT und Blockchain die Basis für die moderne Sharing Economy.
Handel / Kundenkommunikation: Angebote werden datenbasiert optimiert, Kaufempfehlungen benutzerspezifisch formuliert, Preise dynamisch gestaltet, Werbeanzeigen zielgenau eingeblendet und Informationen priorisiert/selektiv kommuniziert. Die zugrunde liegenden Algorithmen nutzen Erkenntnisse, die aus bei anderen/früheren Kundenkontakten automatisch aufgezeichneten Daten abgeleitet wurden (gläserner Kunde, Warenkorbanalyse, Bewertungssysteme). Die praktische Anwendung von Data Science in diesen Feldern ist weit fortgeschritten, insbesondere bei Onlinediensten aber auch im stationären Einzelhandel/in der Gastronomie (Self-Order-Kiosks). Positiv formuliert, wird dem Verbraucher ein einzigartiges, personalisiertes Konsumerlebnis geboten. Verbraucherschützer fordern dagegen einem „digitalen Verbraucherschutz“ und ein stärkeres Bewusstsein für den Umgang mit den eigenen Daten.
In der Versicherungsbranche werden Schadensrisiken unter Betrachtung zahlreicher Einflussfaktoren als Grundlage für die Prämienbemessung für die Risiko-Versicherung quantifiziert. Moderne Data Science Methoden erlauben dabei eine größere Detaillierung und Differenzierung. Algorithmen ergänzen und ersetzen die Arbeit von Sachbearbeitern und Experten.
Im Online-, Kreditkarten- oder Versicherungsgeschäft werden mit Data-Science-Techniken automatisch Betrugsversuche bei Finanztransaktionen detektiert (Fraud Detection, Anomalie-Erkennung). Ein vollkommen neuer Ansatz für die Absicherung der Identitätsauthentifizierung ist die automatische Auswertung der Art und Weise, wie Benutzer Benutzernamen, Passwörter etc. in Formularen eingeben (typing patterns).
Die Analyse von wiederkehrenden Mustern im Bereich der Kriminalität ermöglicht eine vorausschauende Polizeiarbeit. Date Science ermöglicht aber auch eine effiziente und u.U. problematische Überwachung und Leistungsbewertung von Mitarbeitern, Bürgern, Sportlern usw. Problematisch sind hier insbesondere (Einzel-)Fälle, wo die verwendeten Algorithmen ‚irren‘, trotzdem aber automatisiert Maßnahmen mit negativen Auswirkungen für ggf. unbescholtene Betroffene ausgelöst werden.
Im Mobilitätssektor hilft Date Science Bedürfnisse von Fahrgästen und Kunden zu analysieren / zu verstehen / zu prognostizieren und die Angebotsplanung zu optimieren. Flotten und Infrastrukturen werden bedarfsgerecht ad hoc disponiert sowie Fahrgäste und Autolenker situationsgerecht geleitet (Smart Public Transport, Smart Cities). Etwaige Störungen können frühzeitig erkannt, etwaige Fahrzeug- und Infrastrukturausfälle mit Predictive Maintenance minimiert werden.
Datenbasierte KI ist die Basis für komplexe autonome Systeme und für autonomes Fahren.
In der Medizin können Erkrankungswahrscheinlichkeiten und erwartete Krankheitsverläufe durch eine systematische Aufarbeitung historischer Krankenakten und Befunde vorausgesagt werden.
Bilder, Geräusche und Texte automatisch erkennen und analysieren
Vielfältige Anwendungsfälle in unterschiedlichen Bereichen ergeben sich aus der Möglichkeit, Bilder mit Hilfe von Computer Vision automatisch analysieren und klassifizieren zu können:
- automatische Gesichts-/Emotionserkennung (Erkennung von menschlichen Emotionen eingeschränkt möglich)
- automatische Bestimmung von Pflanzen, Pilzen, Tieren – z.B. mit Pl@ntNet, Naturblick, Pilzator (Android) bzw. Pilz Erkenner (iOS), Picture Insect
- Objekterkennung für das autonome Fahren
- automatische Analyse und Bewertung von Röntgenbildern und anderen Bildern in der Medizin
- Handschriftenerkennung und Texterkennung (OCR) als Grundlage für die automatisierte Analyse/Bearbeitung von handschriftlich verfassten Dokumenten
Verbale Sprache und Geräusche können in gleicher Weise wie Bilder automatisch analysiert und klassifiziert werden. Die Anwendungen sind synonym zum Computer Vision: Erkennen von Personen, Situationen und Emotionen (letzteres auch für medizinische Zwecke), Erkennen von Tieren (Vogelstimmen), Spracherkennung.
Texte, die in maschinenlesbarer Form vorliegen (sei es durch Handschriftenerkennung, Spracherkennung oder durch direkte Bereitstellung), können mit Text Mining inhaltlich analysiert und (vor)verarbeitet werden. Praktische Einsatzmöglichkeiten sind der Einsatz von Software-Agenten, um Call Center Tätigkeiten zu automatisieren. Weit verbreitet ist das automatische Übersetzen von Texten, z.B. mit DeepL Translator oder Google Translator.
Bilder und Texte automatisch erstellen
Die automatische, softwarebasierte Erstellung von Bildern, Geräuschen und Texten nach (beliebigen) inhaltlichen und stilistischen Vorgaben ist ein intensives Forschungsfeld im Bereich von Data Science (KI). Mit herkömmlichen Data Science Projekten haben diese Sprachverarbeitungsmodelle auf Grund ihrer Komplexität und des gigantischen Aufwands in der technischen Umsetzung nur noch wenig gemeinsam.
Textgenerierung:
- GPT-3-Modell (Generative Pre-trained Transformer, OpenAI)
- Wu Dao 2.0 (BAAI)
- MT-NLG (Megatron Turing-NLG, Microsoft)
Bildgenerierung (text2image generators):
OpenAI, die in diesem Feld besonders aktiv ist, ist eine gemeinnützige Organisation, welche 2015 von Elon Musk, Sam Altman sowie weiteren Investoren in San Francisco gegründet wurde.

Wie: Data Science?
fachlich
Bei der am Anfang von Data Science Projekten stehenden Exploratory Data Analysis (EDA) werden sowohl Erkenntnisse zu den beobachteten fachlichen Fragestellungen (Prozesse, Ereignisse, Beobachtungen usw.) als auch Beobachtungen zum untersuchten Datensatz (verfügbare Daten, Datenvollständigkeit, Datenqualität) zusammengetragen und begutachtet.
Hierzu werden relevante statische Kennzahlen (Wertebereiche, Mittelwerte, Verteilung: Varianz, Schiefe, Wölbung, zeitliche und räumliche Verteilung, Zusammenhänge: Kovarianz und Korrelation, Unregelmäßigkeiten: Fehlwerte, Anomalien) möglichst vollständig und systematisch erfasst. Die gewonnenen Erkenntnisse werden optisch mit geeigneten Grafiken (Box-Plot, Histogramm, Streudiagramm, Zeitreihen, Correlation Plot Matrices) visualisiert.
Bei der Modellbildung stehen ja nach Art der zu lösenden Fragestellung unterschiedliche Modellarten zur Auswahl:
- Klassifizierungsprobleme: Probabilistic Modeling / Naive Bayes, Logistic Regression / binäre Vorhersagen, K-Nearest Neighbors (K-NN), Support Vector Machine (SVM) / Kernel SVM, Decision Tree Classification / Entscheidungsbäume, Random Forests Classification, Gradient Boosting Machines, Neuronale Netze
- Regression: Simple Linear Regression, Multiple Linear Regression, Polynomial Regression, Support Vector Regression (SVR), Decision Tree Regression, Random Forest Regression, K-Nearest Neighbors (K-NN), Neuronale Netze
- Clustering: Gruppierung ähnlicher Objekte, z.B. mit K-means Clustering
- Assoziationsanalyse – Identifizierung von Regeln von Eingabedaten (z.B. Warenkorbanalyse): Apriori, Eclat
- Spracherkennung und Textanalyse: HMMs
- Computer Vision (maschinelles Sehen) – Objekterkennung, Gesichtserkennung: CNNs
- Zeitreihenmodellierung: Exponential smoothing, ARIMA Modelle und Neuronale Netze (LSTM), auch: Threshold Autoregressive Models (TAR) and Smooth Transition Autoregressive Models (STAR)
Die Wahl des einzusetzenden Modells ist von mehreren Faktoren abhängig, u.a. von der Größe/Menge der Datensätze, der Qualität der Daten (z.B. Linearität), von der konkreten Fragestellung sowie von der Anzahl der unabhängigen Variablen resp. der sich daraus ergebenen relevanten Kombinationen von Eingangsgrößen. So kann ein einfaches Klassifizierungsproblem mit relativ wenigen unabhängigen Variablen über eine (logistische) Regression gelöst werden, während bei einer großen Menge an relevanten Kombinationen von Eingangsgrößen ein Random Forest Ansatz ggf. eher eine zuverlässige Vorhersage sicherstellt. Darüber hinaus gibt es eine historische Komponente, da einige Modelle erst seit kurzer Zeit, andere Ansätze schon viele Jahrzehnte zur Verfügung stehen.
Soll ein Künstliches Neuronales Netz / Convolutional Neural Network (CNN) verwendet werden, so muss dessen Struktur entsprechend der konkreten Aufgabenstellung festgelegt werden. Die Netz-Topologie basiert auf einer Folge von Schichten künstlicher Neuronen (Nodes). Zwischen einer ‚Eingabeschicht‘ und einer ‚Ausgabeschicht‘ existieren ein oder mehrere Zwischenschichten (‚hidden layer‘) – je mehr Zwischenschichten eingefügt werden desto ‚tiefer‘ das Neuronale Netz. Über gewichtete Verknüpfungen zwischen den Neuronen werden durch das Netz Informationen (Aktivierungssignale) schrittweise von der Eingabeschicht bis zur Ausgabeschicht transferiert. Die Verknüpfung der Neuronen untereinander erfolgt im einfachsten Fall ausschließlich vorwärts in Verarbeitungsrichtung (Feedforward Neural Networks), während rekurrente bzw. rückgekoppelte neuronale Netze auch Verbindungen von Neuronen einer Schicht zu Neuronen derselben oder einer vorangegangenen Schicht vorsehen.
Die Ausgestaltung der Zwischenschichten (Anzahl der Schichten, Anzahl der Neuronen pro Schicht, Verknüpfungen) beeinflussen Leistungsfähigkeit und notwendigen Rechenbedarf Neuronaler Netze in signifikanter Art und Weise und sind damit der Schlüsselfaktor für die Umsetzung. Weitere festzulegende Parameter sind u.a.:
- Auswahl der Aktivierungsfunktion (activation function): mit dieser Funktion wird für jeden Node aus der Summe der lokalen Eingangssignale das jeweilige lokale Ausgangssignal berechnet. Hidden Layer und Ausgabelayer werden in der Regel unterschiedliche Aktivierungsfunktionen zugewiesen.
- Auswahl der Kostenfunktion (cost function): mit dieser Funktion werden für Trainingsdaten die Abweichungen zwischen berechnetem und theoretischen Ausgabewert ermittelt. Auf Basis dieser Information werden anschließend die spezifischen Wichtungsfaktoren automatisch über den Backpropagation Mechanismus justiert (Gradientenverfahren).
- Festlegung der Learning Rate
Querschnittsaspekte jeder Modellierung sind Normalisierung und Feature Engineering, wobei letzteres bei der Verwendung neuronaler Netze teilweise bereits implizit erfolgt.
Jedes Modell (jedes Neuronale Netz), welches für Prognosen verwendet wird, muss trainiert, evaluiert und schrittweise optimiert werden. Die dabei erreichte Genauigkeit wird mit geeigneten Metriken beschrieben (RMSE, MAE). Die geeignete Wahl von Trainings- und Testdatensätze sowie die Einschränkung der Anzahl von Parametern und Freiheitsgraden helfen Überanpassung zu vermeiden. Je komplexer ein Modell ist, umso aufwendiger ist die Trainingsphase: bei neuronalen Netzen werden typischerweise tausende von Trainingsdatensätze in zehn oder mehr Iteration durchgerechnet. Je nach Größe des Eingangsdatensatzes und des gewählten Modells kann das Training mehrere Stunden, Tage oder Wochen dauern.
Formal wird zwischen einem Überwachten Lernen, bei dem in den Trainingsdaten neben den Inputdaten auch die dazugehörigen Zielgrößen verfügbar sind, und Unüberwachten Lernen ohne konkrete Zielgrößen unterschieden. Überwachtes Lernen wird bei u.a. bei Regressionsproblemen und Klassifizierungsproblemen verwendet. Beim Unüberwachten Lernen ermittelt das Modell eine geeignete Ordnung der vorhandenen Daten basierend auf Clustering resp. Assoziationsanalyse selbstständig.
Bestärkendes Lernen bildet die dritte große Gruppe von Machine Learning Verfahren und ist eine am natürlichen Lernverhalten des Menschen orientierte, auf „Trial and Error“ beruhende Lernmethode. Sie erfordert eine sehr große Anzahl an Iterationen, während derer das Modell lernt, den Zusammenhang zwischen seinen Aktionen und dem künftig zu erwartendem Nutzen in jedem Status zu approximieren und situationsbedingte Entscheidungen zu optimieren.
technisch
Data Scientists programmieren mit R, Python, SAS, SPSS, STATA, IDL, ANA und Matlab. Ergänzend kommen übergeordnete Tools, Sprachen und Frameworks für das Datenmanagement zum Einsatz, insbesondere im Kontext der Verarbeitung großer Datenmengen (Big Data/Big Computing, verteilte Cluster/Parallel Computing, Data Warehouse Backends): Hadoop, Apache Spark, Scala, DBI, ODBC. Am anderen Ende der Skala sind einfachere Data Science Anwendungen auch mit Tableau oder Excel (Schwerpunkt Visualisierung) resp. JavaScript (Schwerpunkt einfache Integration in vorhandene Systemlandschaft) auf herkömmlichen Maschinen möglich.
Die beiden zentralen Sprachen R und Python sind populäre Open Source Sprachen mit einer großen Community und zahlreichen frei verfügbaren Erweiterungen (Packages, Bibliotheken). Die Anwendungsfelder der beiden Sprachen überlappen sich, wobei die Schwerpunkte von R eher in der Analyse und Visualisierung (Mustererkennung) sowie im akademischen Bereich liegen, während Python in komplexeren Anwendungen zum Einsatz kommt.
R Code ist über den Pipe Operator %>% und weiteren Eigenschaften von dplyr ausgesprochen gut nachvollziehbar programmierbar, gleichzeitig aber weniger intuitiv in Funktionen strukturierbar (non-standard evaluation / NSE). Für R funktioniert das Package Management sehr zuverlässig (CRAN), während unter Python zwei konkurrierende Manager existieren (pip und Conda) und insbesondere unter Windows die Installation von Entwicklungs- und Ablaufumgebungen sehr zeitintensiv sein kann. Interaktive, webbasierte R-Applikationen lassen sich in R über Shiny direkt erstellen, während bei Python eine maßgeschneiderte HTML/Javascript Ergänzung benötigt wird.
Für die effektive Umsetzung Neuronaler Netze stehen inzwischen sowohl für R als für Python mehrere Open Source Deep Learning Frameworks zur Verfügung. Sprachenübergreifende Frameworks existieren auch für die effektive Implementierung von Gradient Boosting Lösungen: XGBoost (Tianqi Chen, 2014), CatBoost, LightGBM.
Für einige Fragestellungen insbesondere im Bereich der Bilderkennung können vortrainierte Modelle eingesetzt werden.
Wenn die Rechner-Infrastruktur fehlt, oder wenn die Steigerung der Effizienz des Entwicklungsprozesses für Standard-Aufgaben im Fokus steht, kann die Analyse der eigenen Daten auch mit externen MLaaS-Plattformen erfolgen, wobei jedoch entsprechende Lizenzkosten anfallen (Machine learning as a service).
Der Mensch
Während Standard-Anwendungsfälle der Datenaufbereitung durch KI immer stärker automatisiert werden, liefern individuelle Data Science Lösungen maßgeschneiderte Ergebnisse. Auch strategische und inhaltliche Führung können Maschinen nicht wirklich gut. Hier wie dort besteht zukünftig weiter Bedarf, die neue Welt individuell gestalten zu helfen.
Data Scientists benötigen Expertise in statistischen Methoden, programmiertechnische Fähigkeiten sowie Businessanalyse/Domänenwissen. Eine proaktive bereichsübergreifende Kommunikation ist der notwendige Schlüssel zum Erfolg von Data Science-Projekten, insbesondere im kommerziellen (nicht-akademischen) Umfeld.
In umfassenden Projekten wird zwischen Data Scientists, Data Architects, Data Engineers und Data Analysts unterschieden. Ein aktives und kontinuierliches Management (Leadership) des Data Science Teams ist unerlässlich. Die besondere Herausforderung der Leitung von Data Science Projekten ist, dass diese Projekte u.U. sehr explorativ und ergebnisoffen angelegt sind.
Data Scientists bilden weltweit eine aktive und offene Community, die sich über einschlägige Plattformen wie Kaggle, rOpenSci, R-Ladies, KDnuggets, DataCamp, Towards Data Science organisieren und austauschen.

Abgrenzungen
Verwandte Disziplinen zu Data Science sind Data Analytics, Data Mining, Decision Science, Business Analytics, Business Intelligence (BI), DMAIC und Big Data (Abgrenzungen fließend).
Der Begriff der Künstlichen Intelligenz (KI) stellt einen Sonderfall dar, da er bereits in den 50er Jahren geprägt wurde und primär empirisch (nicht-technisch) definiert ist: Eine Maschine wird als ‚intelligent‘ bezeichnet, wenn eine Testperson bei der Kommunikation mit dieser Maschine nicht unterscheiden kann, ob der Kommunikationspartner ein Mensch oder ein Programm ist (sogenannter ‚Turing-Test‘).
Eine in diesem Sinne intelligente Maschine muss nicht zwingend datenbasiert funktionieren. Vielmehr ist bis zu einem bestimmten Umfang eine regelbasierte Umsetzung möglich, in dem Fakten, Ereignisse oder Aktionen mit konkreten und eindeutigen Repräsentationen erfasst werden und auf diesen Symbolen mathematische Operationen definiert werden („symbolische KI“). Für komplexere Probleme werden jedoch datenbasierte, in der Regel selbst-lernende Ansätze benötigt („statistische KI“).
Die beiden Bereiche Data Science und Künstliche Intelligenz überschneiden sich somit gegenseitig, ohne dass einer der beiden Bereiche den anderen vollumfänglich abdecken würde.
Mit Data Storytelling wird die professionelle Vermittlung von Erkenntnissen anhand von Daten beschrieben. Data Science Vorhaben liefern als inhaltliche Grundlage aufbereitete Daten, die graphisch und dramaturgisch für ein Plenum aufbereitet werden. Data Storytelling verbindet somit Data Science mit Kommunikation und Design, um Datenzusammenhänge nachhaltig und zielgruppengerecht zu transportieren.
siehe auch: